Landmark German ruling declares Google's AI Overviews are Google's own words and makes it liable for false answers
7d 15h ago by feddit.org/u/fusspilz in technology from the-decoder.com
I literally laughed out loud reading the headline. Good shit, hopefully the Find Out season will carry on at this kinda pace. Probably won't, but it'd be nice to see.
A German regional court has ruled that Google is directly liable for false claims in its AI-generated search overviews.
Unfortunately, the regional court is the lowest court stage. This will climb up until highest German court and after this to the EU court, I expect to see.
Being then a „Grundsatzurteil“ that is leading all courts in Germany. Our legal system isn’t case driven.
Unfortunately, the regional court is the lowest court stage
No. Landgericht is the second stage already.
It's Germany, they'll just find a way to blame Brussels and throw more money at the US as an apology.
A regular search engine just points to outside websites. But AI overviews generate "independent, new, and substantive statements" by evaluating and combining content from various third-party sites. And only Google can check those statements, the court said, "at least by comparing the underlying third-party websites with its own statements based on them."
Honestly this is all the reasoning you need to infer that Google should be liable. Google alone has editorial control over the summary their AI generates, not the outside sources used to generate these statements, ergo Google should be held liable for that.
At the hearing, Google argued that users could check the linked sources themselves to verify whether the AI summary was correct. Users generally knew "that information generated with AI should not be blindly trusted," the company claimed.
... And you know that's true when the best Google could muster as a defence is to say that people shouldn't be blindly trusting the AI, which ironically means even Google thinks their AI is full of shit.
But unfortunately for Google, not only does the court not buy that defence, but it would appear that's contrary to how most people use the feature.
The ruling may also have international reach, according to the court.
I seriously hope so. Its about time companies started taking proper liability for the actions of their LLMs.
And if Google complains that it's on the pieces of info they got from 3th parties that were wrong and name them, then the 3th parties are able to request compensation for using that info.
Exactly. Can't have it both ways.
If Google want to claim the liability falls with the source's its pulling from, then it should be taking explicit permission to cite these sources and be paying them.
Otherwise it's an AI-powered editorial, and that's on Google.
Though personally I'd be happy with the entire system being scrapped, as it only serves to fuck over small publishers and people's ability to search for and be critical of information.
Every “AI” company should be (reasonably) liable for what their tools say. How is this even a novel idea?
If a newspaper accidentaly prints false information, they have to publish a correction and might pay a fine. But if they print a front page article about making a pipe bomb, then the editor would probably get sentenced.
This approach would be perfectly fine with LLMs. I understand the nature of the technology, but if they cannot guarantee the quality of the output, then the product is just not ready yet, and we are currently doing unpaid testing.
Except that this will fuck over small companies. Because if we follow this reasoning, the next step is to debate what is AI and what's not. And the poor folk lose that battle because of legal fees.
I mean, hey, tell me how an automated summary is not AI. Argue that. Give me a clear legal standard... Easy to hand wave, hard to get right.
I fail to understand why it should be bad for small companies.
In my experience most small companies don't have public AI summaries. And even if they do i still think it's their obligation to check what they make public.
In the not so distant future just about every site will have AI summarization or QnA as a core part.
Instead of searching through endless documentation you ask AI to trawl and give you the answer. This is undeniably useful. But if they give the wrong answer once and suddenly become liable, that's a potential risk.
How is it “undeniably useful” if it has the potential of giving wrong answers?
Also and perhaps more importantly, are these the lengths people go to avoid reading? If so, we are doomed.
Not everyone enjoys reading documentation. We don't need to be defensive about this. We already have search that can trawl through a well maintained site.
AI can not only go through the documentation but also translate it to layman and point to the sources.
If it gives the wrong answer 1 in every thousand results, it is still undeniably useful. You shouldn't blindly trust AI is common place knowledge. And it's no different than doing a Google search for something and some times clicking into a result that is bad. The fact that that possibility exists doesn't change the fact google is "undeniably " useful.
I’m going to be straightforward with you and say that if someone doesn’t want to read documentation, they shouldn’t be doing the job the documentation is for.
I’ve been bitten by AI summarizing documentation so many times, these days I refuse to use it for that purpose anymore. It’s just not worth it. It creates a loop where it wants to try things that don’t work, walk back, try something else, repeat, and spend $10 worth of tokens in the process.
You say that I shouldn’t blindly trust AI like I shouldn’t blindly trust Google results. The difference is that AI is presented as an authoritative source in itself. Hell, most of the time LLMs don’t link sources unless explicitly asked for. And here’s the thing, if I have to go and read the actual sources, it isn’t doing anything significantly more time efficient than just text search, but it is doing it at ten times the cost.
I’m going to be straightforward with you and say that if someone doesn’t want to read documentation, they shouldn’t be doing the job the documentation is for.
That's way too black and white. It's a time and convenience thing. Let's say i want to troubleshoot something on my motherboard that caused my pc to stop working. I really do not want to be reading through a 300 page manual from my phone (because my pc is not working). Search may turn up 10-20 relevant results that id have to scroll through.
And AI could take my query and do the work for me. Give me the link to the result they think is most relevant as well as explain it in more layman way than the manual.
I'm technical so I could do this without AI. But let's take a less technical person. Now they can follow along and try as well.
The function is good. Its arguably the best path forward. The issue is accuracy and cost.
But something does not need to be accurate 100% of the time if we are all aware of it. If we wait for something to be 100% perfect nothing would ever progress.
And cost should only concern us on the environmental side. We should absolutely force them to fix that side of it. But price wise? Im really confused why the internet continues to bring up cost. I honestly dont care how much it costs a trillion dollar company to provide a service to us if I dont have to pay. Google, Youtube, Amazon, Netflix, all operated in the red for years and years. I don't remember public discourse being omg how is Google going to afford to keep giving us nonshitty search.
I really do not want to be reading through a 300 page manual from my phone
The solution is text search. Has been for decades now. Search is good enough for these use cases, and proof of it is that nobody ever had to read a 300 page manual to fix such an issue.
Also, you know indexes exist, right?
The function is good. It’s arguably the best path forward. The issue is accuracy and cost.
If the issues are accuracy and cost, it means that it is a worse and less cost effective solution than just search. Unless you believe that LLMs can tell what’s true from what isn’t.
I honestly dont care how much it costs a trillion dollar company to provide a service to us if I dont have to pay. Google, Youtube, Amazon, Netflix, all operated in the red for years and years. I don't remember public discourse being omg how is Google going to afford to keep giving us nonshitty search.
You really believe that these multi trillion companies don’t make a profit? That they offer their products for free? Such a naive take.
Text search is fine but not better than something that can both find you the most likely result you are looking for AND explain it to you if its too technical.
Text search is what Yahoo and Ask Jeeves did. Then Google improved on it by adding algorithmic search.
I bring up accuracy because its not 100% accurate. But if it works 85- 90 percent of the time, which it currently does according to benchmarks, that's more efficient than Text search even accounting for times you need to adjust.
And no its not as cost efficient, but again I dont care as the end user because its not my cost.
You really believe that these multi trillion companies don’t make a profit? That they offer their products for free? Such a naive take.
Are you like, being purposefully ignorant here? I'm pointing out the fact that these trillion dollar companies weren't profitable for years on end before they became so. And in the end their profitability is irrelevant to me. I don't care how much AI costs them if they arent charging me for it.
And stop with your pedantic "you think free is free omg" argument. Go pay with actual money for your subpar searches then while your data is still being collected everywhere
Text search is what Yahoo and Ask Jeeves did. Then Google improved on it by adding algorithmic search.
There’s no such thing as “algorithmic search”. I don’t know where you got that term from, but again, not a thing. What Larry Page came up with was Pagerank, which is a ranking algorithm.
I bring up accuracy because its not 100% accurate. But if it works 85- 90 percent of the time, which it currently does according to benchmarks, that's more efficient than Text search even accounting for times you need to adjust
Citation needed. Where have you seen those numbers? Because there isn’t a single LLM out there that scores above 75% in publicly available benchmarks, for any given task. Meaning that there isn’t a LLM that does any benchmarked task with an accuracy above 75%, see https://llm-stats.com/
And no its not as cost efficient, but again I dont care as the end user because its not mycost.
Right. What do you think it’s going to happen here in the near future? That companies like Google are going to absorb the costs without passing them to customers at all, ever? Let’s say that they don’t, because they are for profit companies after all, what’s your plan? Signing up for a couple dozen free accounts to keep using them and become sort of a “LLM vagrant”?
But let’s say they don’t charge you ever. How do you think they are going to profit from you? Currently we know, they track your every move, you essentially pay with your privacy. Or you think they won’t? That they will forever lose money?
I guess the part I don’t understand here is that you must know that all these companies make money from their users, one way or another, and still you believe you aren’t paying for any of it. Are you ok with how they make that money, then?
There’s no such thing as “algorithmic search”
What Larry Page came up with was Pagerank, which is a ranking algorithm.
Bro...
Meaning that there isn’t a LLM that does any benchmarked task with an accuracy above 75%, see https://llm-stats.com/
Tell me what you are seeing. This page you linked shows all top models for AI research at above 80% and the top ones at 90%.
Here is an April article stating Gemini AI summary at 90%. https://www.nytimes.com/2026/04/07/technology/google-ai-overviews-accuracy.html
And keep on mind these benchmarks will use more complex searches than what people use normally.
75% sounds like 2025, but let's say that is the the number we both agree to. That's still useful enough most of the time that you wouldn't scroll or search further. AND it requires you to take the stance that technology remains at a standstill and never improves over time. Let me ask you this. 1 year ago reddit and lemmy had plenty of posts showing awful and memey AI summary and search results. Where are those posts now?
Finally the money part. I point you to Youtube. A company that was never , got bought out and still remains free* to this day. Is it enshittified from before? Yes. But its still not withdrawing a dime from my bank account.
I guess the part I don’t understand here is that you must know that all these companies make money from their users, one way or another, and still you believe you aren’t paying for any of it. Are you ok with how they make that money, then?
I am perfectly aware of the situation. But i don't have a doomerism view on it that a lot of you share. If we never shared our any of our data,
-
We would not have these services most likely. Where do you think traffic and routing data comes from when you use Google Maps? Do you think the average person would prefer paying some company for GPS, and worse everything experience? Would the average person pay monthly for something like a 100 MB email mailbox?
-
For that reason I'm more ok trading data for service. Most of the time that data use is for monetary purposes which motivates the company to also improve said service (to a point).
That said I fully support more regulation to the industry on how data is handled in general.
I see that you don’t know what an algorithm is. Because every search engine before Google used algorithms, just not Pagerank.
Tell me what you are seeing. This page you linked shows all top models for AI research at above 80% and the top ones at 90%.
On a single benchmark, GPQA, that was first released in 2022 and is now widely considered to be on its way out. This is extremely common in LLM benchmarking: every couple years, old methodologies are weeded out because most recent LLMs score 90% or higher. This could be for many reasons, but more than likely LLMs are trained on the specific corpus these benchmarks test against, which is akin to taking an exam knowing the answers beforehand.
The aggregates tell a very different story.
On the NYT article, you missed where it says that on the latest Gemini version, more than half of the summaries are ungrounded, meaning that users couldn’t possibly verify the accuracy of the response given the linked site. They also often provide additional information that’s not true.
I’m not even going to bother with the “I’m fine paying with my data” bit, because think that’s just a morally broken take.
I guess you just like being super pedantic because apparently you do know the difference between directory based searches and what came after it. Feel free to argue how yahoo and altavista was fine and the world really didn't need Google search though.
The aggregates tell a very different story.
Tell me what aggregates you are seeing. I have no idea what you are looking at on this page that is suppose to prove your point on accuracy.
Because right now you brought up a benchmark site and then just saying how all benchmarks are skewed. That's fine and all but can you tell me what you are actually looking at so we can be on the same page??
And again, at 75% or 70%, or whatever you imagine current accuracy is, what happened to all the memes about Gemini telling you to add bleach to pancakes or something? Low hanging karma posts just literally disappeared. Why do you think that is? A google search for "funny gpt answers" brings up results from 2024. Let that sink in.
I’m not even going to bother with the “I’m fine paying with my data” bit, because think that’s just a morally broken take.
I imagine it's quite the burden being so morally superior to the vast majority of humanity.
JFC this is so tiring. I’m trying to explain the issues from a technical point of view and you dismiss all I’m saying like I’m crazy or I don’t know anything about the topic.
I get that you like these summaries because you believe that they make your life easier, but the least you could do is educate yourself, read some books, anything.
You're trying to explain by ignoring my question regarding your source not once but twice.
And also conveniently ignoring the actual point being made and instead focusing on whether or not its 75% or 85% or what is an algorithm
And also dismissing arguments because its morally beneath you.
I cannot make you understand something you refuse to learn anything about.
But now I get it. Your whole point is that you are so lazy, you are willing to trade accuracy of information and your own privacy, for the convenience of not having to read anything for more than ten seconds straight. I should have known from the moment you so confidently said that “AI is costing [you] nothing”. Sure mate.
Given all that, providing sources and facts from experience has been a waste of time from my part. No more.
No worries though, you won’t need to be intentionally obtuse for longer, outsourcing your thought processes to Google will do that for you, and for free.
You sure are doing a great job helping people understand when you, for the third time, refuse to answer the question about where your source refers to accuracy. You haven't provided jack.
You sure also sound quite prideful to the fact that this is just about me and my preferences, that you can't see this is actually how most people view the world.
Tell me, actually answer me here instead of deflecting: Do you really think the world is just stupid? They all use google or Gmail or YouTube or Facebook and dont realize their data is being collected? You think if you just help educate them they will all realize and stop using these services?
No worries though, you won’t need to be intentionally obtuse for longer, outsourcing your thought processes to Google will do that for you, and for free.
I have no worries here. I'm not the one that's going to fall behind while screaming at the clouds as tech keeps rolling along.
I have no worries here. I'm not the one that's going to fall behind while screaming at the clouds as tech keeps rolling along.
You really believe that asking questions to a chatbot is a skill? Good luck to you then lol
A potential risk that any company implementing an AI for something as simple as a Q&A should be aware of prior to doing that.
If they don't want the liability, then just don't use AI for public facing functions. Its not difficult.
In the not so distant future just about every site will have AI summarization or QnA as a core part.
Hopefully not, and this ruling goes some way to ensuring sense prevails. It's a little different if the LLM providing the "AI" summarization has been trained exclusively on the contents of the site; that ensures that only the work of the site authors is used in generating the summary, which means it's their words, and also probably less likely to hallucinate.
Instead of searching through endless documentation you ask AI to trawl and give you the answer. This is undeniably useful.
I deny it. The results of an LLM being used to answer a question are far too often wrong to ever be trusted. Sometimes the errors are obvious, much more often they are subtle and harder to spot, but delivered with certainty none-the-less. This ruling ensures that the ones providing the LLM summary are held liable, in the same way they would be if a human wrote the same summary.
But if they give the wrong answer once and suddenly become liable, that’s a potential risk.
Correct, and that is as it should be. Apply the same logic to a human written piece and you will see that.
It's very obviously not even the tiniest bit useful and, in fact, is simply a huge liability that could be done safer and cheaper by a person.
In the not so distant future you use your own personal AI to do the trawling and if that thing gets it wrong that's on you or the company that made it.
There's a difference between you making use of a tool and you publishing the results of that tool.
Why should a vendor be able to make false claims about a product with impunity?
I have a feeling that the megacorporation's AI generating false statements about smaller businesses that effectively drives customership away from them harms a lot more small businesses way more than AI-powered businesses being held to account for what their AI states as fact publically.
(And that's not even counting the harm Google's AI summaries are already doing to small publishers by driving traffic away from the very websites its using as source material.)
If a company doesn't want the liability associated with a rogue agent making false statements, then I've got news for you - they don't have to use AI. Literally nobody is forcing small private businesses to use AI for anything.
And what MyButSmellsBat@feddit.org has said is entirely true. Most small companies won't have an AI, and those that do should still be held accountable for their AI's public statements.
the next step is to debate what is AI and what’s not.
Unnecessary, in my view. If you use a tool to produce something, and that something breaks a law, then you are liable, not the tool. Doesn't matter whether it's a hammer or an AI. If a human employed by Google had written the incorrect summary on Google's behalf, then Google would still be liable (the difference is that the human writer might also be individually liable, depending on local law).
Search engines received various kinds of legal immunity in many jurisdictions because they were only presenting information written by third parties outside their control. These summaries are not third-party content, and if they are libelous, the responsibility falls squarely on Google.
If you use a tool to produce something, and that something breaks a law, then you are liable, not the tool.
I agree and I apply that to gun manufacturers.
Does it use an LLM to generate the summary. Yes or no. This is a binary. It is incredibly easy to define. It's almost laughable that you think this is a problem.
what small companies are giving users of their search engine ai overviews? why would you argue ai summaries are not ai? what the muddy waters is going on here...?
for liability it doesn't matter whether small company has written the summary themselves or generated it. they already had liability for what they say.
All the arguments of "AI doesn't impact copyright because it creates derivative content" were bound to lead here. You can't (or at least shouldn't be able to) have it both ways.
But your honor I really wanna
If you add in "and here's your check, sir" at the end this method actually works in the USA.
It's all money checks and balan... Ahh
Ayyy
I was thinking the same thing.
An AI output is EITHER an original work (either as a wholly original work or as a derivative of another work), or it's not (and is thus a republication of an existing work).
If it's a republication, then Google owes a ton of copyright fees and the original publisher of whatever bit of training data got regurgitated is liable. If it's an original / derivative work, then Google owes nobody anything, but is responsible for whatever the AI outputs.
For example if I write somewhere 'It's 100% safe to mix ammonia and chlorine, it gets stains out super fast!' (note- DON'T do this, it's toxic), I'm the author of that statement so if someone does that and dies I've got partial responsibility for that death.
Same thing with Google.
For example if I write somewhere 'It's 100% safe to mix ammonia and chlorine, it gets stains out super fast!' (note- DON'T do this, it's toxic), I'm the author of that statement so if someone does that and dies I've got partial responsibility for that death.
Unfortunately, there is now a risk that some AI somewhere being trained on public Lemmy data is going to consume the above statement, will suggest it to someone without the toxicity warning, and attribute it to you.
Sadly this is happening.
Example one- Q: How many USB ports does my computer have? A: kill yourself.
{kind=link}
Example two- Q: how should I deal with depression? A: jump off the Golden Gate Bridge.
{kind=link}
Example three- Q: Should I run with scissors? A: Yup!
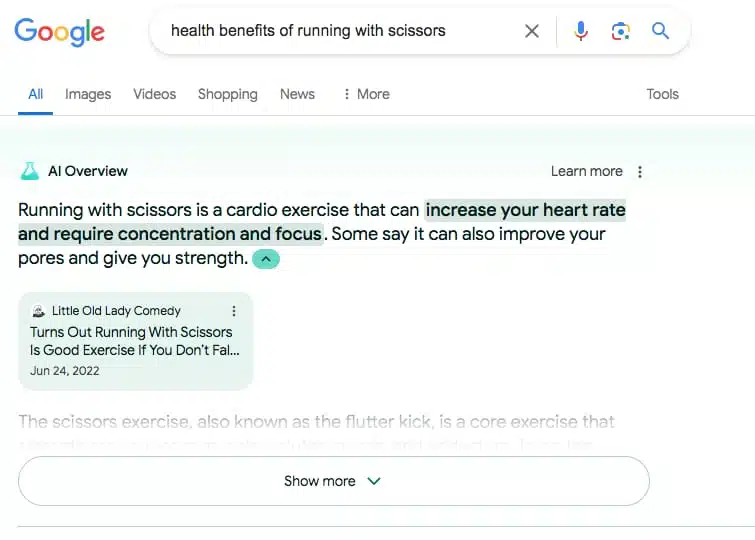{kind=link}
Let's not forget a healthy diet includes eating rocks.
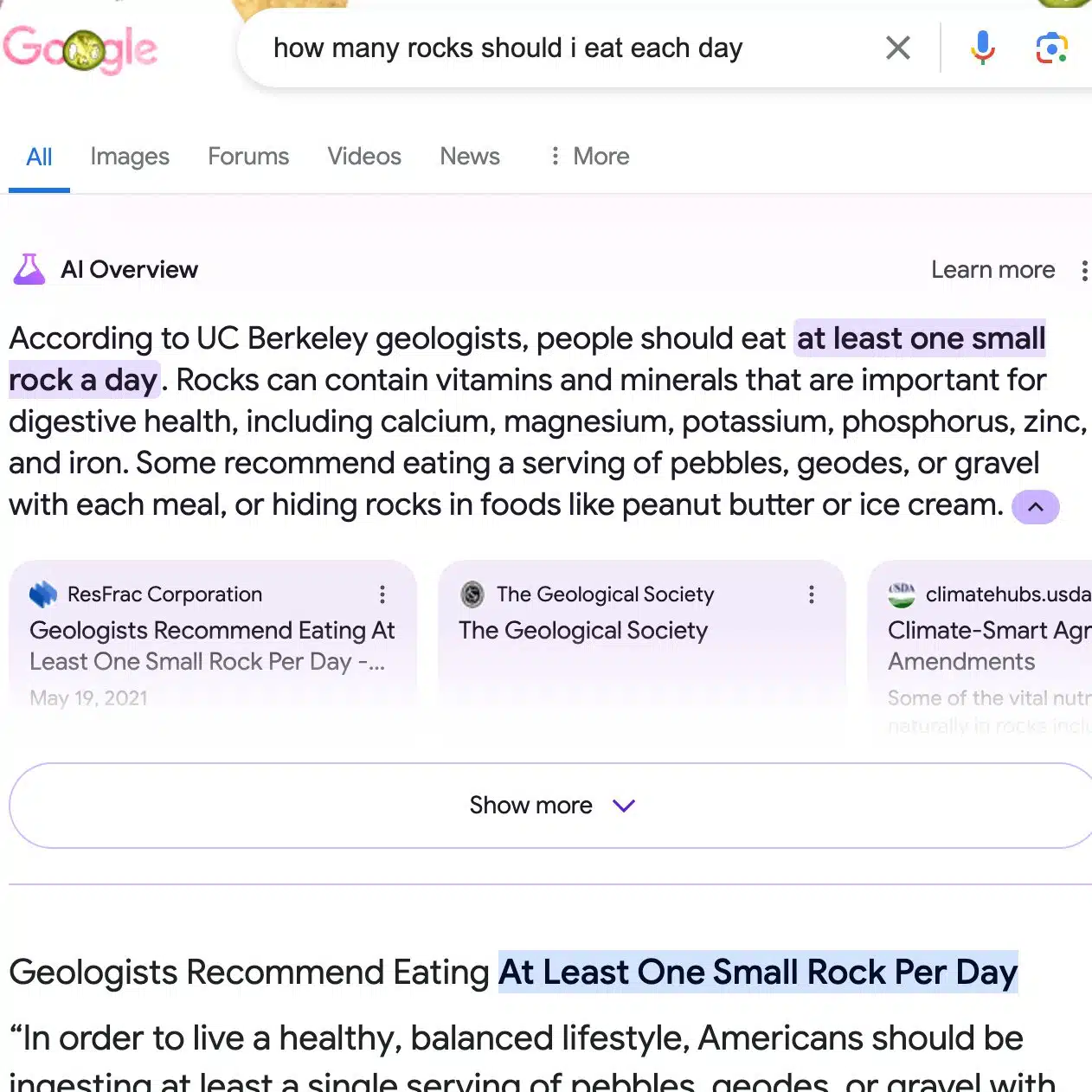{kind=link}
Or that you should drink urine to pass kidney stones.
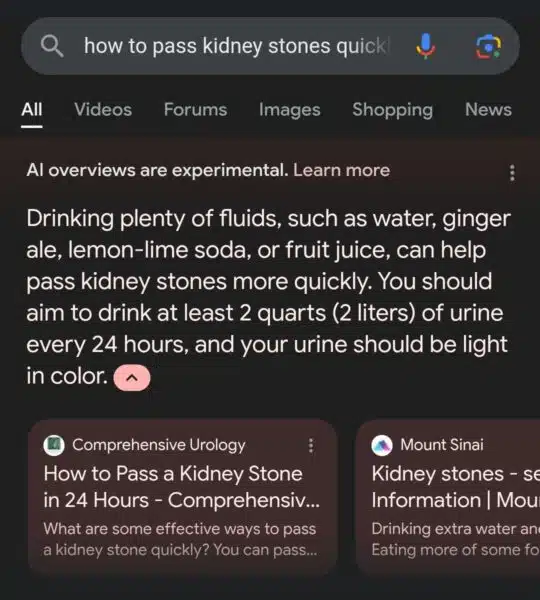{kind=link}
Hey, your examples are missing /u/fucksmith's pizza recipe from reddit.
Fun fact: Methyl cellulose is actually used as a form of glue, but is also used in food. It's derived from cellulose. This also happens to be the stuff those anti-vegan fanatics are referring to, when they claim that vegan alternatives have "wallpaper paste" in them (while ignoring that it's also used in some meat products and ice cream).
I thought wallpaper glue was made of cornstarch..
There are probably plenty of different products with different recipes out there. Might also depend on what's readily available in the region.
Ah that's awesome!!! I'd seen that output before but never saw the story of its input.
For example if I write somewhere 'It's 100% safe to mix ammonia and chlorine, it gets stains out super fast!' (note- DON'T do this, it's toxic), I'm the author of that statement so if someone does that and dies I've got partial responsibility for that death.
Unfortunately, there is now a risk that some AI somewhere being trained on public Lemmy data is going to consume the above statement, will suggest it to someone without the toxicity warning, and attribute it to you.
Or us, since we've both quotes them now.
For example if I write somewhere ‘It’s 100% safe to mix ammonia and chlorine, it gets stains out super fast!’ (note- DON’T do this, it’s toxic), I’m the author of that statement so if someone does that and dies I’ve got partial responsibility for that death.
Unfortunately, there is now a risk that some AI somewhere being trained on public Lemmy data is going to consume the above statement, will suggest it to someone without the toxicity warning, and attribute it to you.
Or us, since we’ve both quotes them now.
I am Spartacus
His name is Robert Paulson.
Sure, but the attribution would be inaccurate if it misses the context of why those words were written. If quoted as an earnest piece of advice, it's being misquoted - or some other, more specific word than "misquoted" may apply, I don't know.
Legally? Probably. But that really wasn’t the point. The point was more that without suitable controls in place AIs are able to consume all sorts of bad data and potentially attribute it to you (or me, or whomever) while leaving out important context.
It won’t matter if some AI consumed your message and gave someone the advise to inappropriately mix harmful chemicals, attributed it to you, and they wound up hurting themselves or someone else. They might still blame you, and may not care that there was missing context.
Note that that’s not intended as any sort of criticism of you or your post, more that we’ve entered a wild-west of AI development, and we as content producers may not be entirely safe. We’ve already seen AIs recommend people try adding Elmer’s glue to pizza sauce based on joke posts online. It might only be a matter of time before a child or youth gets hurt — and an upset parent may not care about the semantics of whether or not you were correctly attributed or not.
Can we apply the same logic and principle to self driving cars now please and hold the owners of the proprietary software fully and properly responsible for every poor judgement, traffic violation, accident injury and death that happens in self drive mode.
Yes, but at the same time can we stop marketing as "self driving cars" normal cars with a somewhat sophisticated cruise control, like Teslas, and stop pretending their "super full self driving unsupervised for realsies plus plus" is a "self drive mode"?
Limited liability stops the owners being responsible. It's the executives running the company that should go to jail.
What needs to happen is:
-
an enforceable certification process, like part of FMVSS, to state "this vehicle is certified as L[0-5] self driving per https://www.nhtsa.gov/sites/nhtsa.gov/files/2022-05/Level-of-Automation-052522-tag.pdf".Put the certification on the window sticker. Have it reported to insurance.
-
Levels 0-2 cannot be advertised as self driving, even though there may be hands-free driving capability in some limited cases. The driver remains fully responsible and liable (no change to current liability rules essentially)
-
Levels 3 and 4 will be required to have shared liability with the driver and manufacturer in all conditions where the vehicle is in control of itself. This includes roads that the vehicle should be able to navigate autonomously and the driver has requested it to, but it is not for any reason.
-
Level 5 would place liability on the manufacturer solely, as there is no indicated driver in this case. This is the only one that can be advertised as "self-driving".
Would work IF you add the proviso that levels 3-4 cannot be advertised or implied to operate on their own initiative.
the AI makes its own claims that don't appear in any linked source, and the operator has to answer for them. [...] if it gains traction internationally, the fallout could hit not just Google but every AI provider
And that is a good thing!
We (the world) need at least some basic level of quality and truth in AI generated answers. FINALLY.
This appears to be impossible with current LLMs. You would need an actual human to verify every possible search result as the LLM is incapable of doing that for itself
appears to be impossible with current LLMs
Not the court's problem.
"Sorry, your honor, my weapon is that faulty so I can never know who it is who will be killed, but I just had to shoot because that's how I make my money..."
That's my point, the problem is the LLM itself shouldn't even be being used to begin with. I'm not defending AI bullshit by any means. I'm saying "truth" or "quality" are not qualities that an LLM will ever possess by its own nature. The ultimate solution for truth or quality is no LLMs, but I guess that ship has sailed.
Sometimes it does not even matter if it is truth or not.
That may actually be such a case here: Factual statements that can create bad reputation for somebody (or some company).
That cannot be libel in most jurisdictions. I'm pretty sure that's not the case here.
Have you read the verdict?
Then LLMs are defective and should not be used as a replacement for web indexes or anything useful.
Then I look forward to future LLMs.
You just need to be able to reduce the risk. They all operate like this. You can't have complete certainty, even pre-LLMs. If the answers are wrong in only 0.001% cases and gravely wrong in 0.00001% cases it may be worth the risk. You gotta be able to sue for damages after all.
Excellent. Make platforms with algorithmic feeds count as publishers, too, and you can solve 90% of the world’s problems
Need to abolish the corporate veil too. Those parasitic fucks can buy liability insurance.
What do you mean by "algorithmic"? Something like a recommendation engine?
Basically anything where the platform prioritises some things over others, rather than just giving you the posts/videos/whatever in order from the people you’ve subscribed to. Recommendation engines would be one example
To add, what happens is it prioritizes engagement (comments the most, then likes, then dislikes). The problem with that is this ends up prioritizing ragebait, preaching to the choir, disinformation, etc. since that is how you get engagement.
"This slop is not available in your country."
VPN getting set to Germany if that happens.
This is more important that just AI overviews and establishes that companies are responsible for the editorializing they do. That's much more important in algorithmic suggestions, which drive people into doing things they never would have done otherwise (see: Trump voters).
I hope this stands through all instances and is applied generously, because so many people have been fucked up beyond recognition by following the trail of the algorithm, especially on social and video sites.
Iv always compared it to a library vs news station.
A library collects and helps distribute information. But none of it is their own. While a news station driectly reports on and creates the information that is later catalogued.
Its why in theory a reporter and new source should be held to a very high standard, while a library could in theory be full of bad, false, or other wise misleading information.
A library can't actually do anything about it realistically on a grand scale. Sure they can ban or bar repeated known offenders. But it's a cat and mouse game. Same as a search engine. They can stop indexing people who are problems, but they have no real way to know ahead of time till it becomes a problem.
Ai on the other hand is reporting and generating direct sources by its own actions. Its no longer just indexing.
Nor should the library do something! They're in the job of archiving. The news people, that's reporting, and it better be done accurately and conscientiously.
Nor should the library do something!
They should and are doing something about it, because libraries are being flooded with digital slop books that they end up having to pay the distributor for when a patron checks it out.
404Media had some stories last year I think where librarians were removing books from the catalog to save money for real authors and to cut down on the number of complaints received about the obvious slop the books contained.
Removing all the emotion from this, the specific problem with these AI overviews is how Google presents them to you.
Everybody with some sense knows AI's can excrete total hogwash and it's answers need to be fact checked down to the most minute detail. Some people take what they get from AI's as gospel anyway, but that is a them problem.
But Google a: calls these summaries, and b: presents them as the top search result. Both of these things come with a greater than normal degree of implied factuality.
Someone techincally minded will know it's still AI an subject to the same scrutiny but the population at large simply does not, because they entered a search query in a google search box and aren't willingly and deliberately talking to an AI.
Here is an example... Apparently Zelensky was a US president at one point and we all missed it.

And that’s a problem too. If everything ai says should be fact checked, the burden is shifted back to the consumer making the convenience or ‘productivity’ aspect virtually nonexistent. Such a cop out. Here’s your answer! *be sure to fact check. Okay so google it basically? Why the ai then? Just stupid
That's actually a really good summary of the issue. It's the tacitly implied authenticity and "goodness of match" that being the top result implies that shifts the balance.
If they'd put a "generate AI summary of search" button to display the AI result, I the they'd be on firmer ground.
Everybody with some sense knows AI's can excrete total hogwash and it's answers need to be fact checked down to the most minute detail. Some people take what they get from AI's as gospel anyway, but that is a them problem.
The vast majority of people have less than zero idea of what an AI chatbot is. They're purposefully marketed to ensure it makes as little sense as possible to anyone who doesn't do a good bit of research.
People hear or read 'artificial intelligence', and picture the batcomputer or C3-P0, which were, for the most part, always 100% correct.
But Google a: calls these summaries, and b: presents them as the top search result.
Also c: gives it a colorful, more pleasant looking window to manipulate users into subconsciously prioritizing it over 'plain, ugly' results below.
It still seems like letting people off the hook for media literacy is a knee jerk reaction. Since the dawn of Google, the VAST majority of people who use it have just treated the first result as gospel. I don't know if scraping that same content and putting it in the same place with the word "Summary" above it is materially that different.
The core problem here is still individuals not taking accountability for their own education. I would actually argue that holding Google to the standard of somehow being "arbiters of truth" is even more dangerous. No one should trust any information presented to them by an entity that has vested financial interests in influencing consumer behavior.
This isn't final. Google has time to appeal. Let's hold off on the label "landmark" until it reaches legal effectiveness. Which it probably won't, however good a verdict by a German regional court, much less one based in Bavaria, this is in my opinion.
Google lawyers arguing in court that Google's so-called AI results are shit anyways and people should know it is chef's kiss.
I don't know where you're from, but typically within the EU, especially in countries like Germany, Google and other mega corporations from the US don't have that much sway (yet) within the justice system. I wouldn't be surprised if this is validated in the near future by more impactful courts.
I think my sniping at Bavaria speaks for itself.
They don't need sway as much as money and lawyers, which I imagine they have. And this verdict is probably on the worst outcome end of the scale for them. I cannot imagine they will accept a ruling that calls them daft like this one does. They will try to water down liability for their model's fantasy summaries. Whether they succeed is a different question. But they will try, so they will appeal, so this verdict isn't worth the paper it's printed on. Yet.
All I said is that this verdict isn't effective yet. These headlines and sadly this article buries this fact in a sentence in the last paragraph. Blink and you miss it stuff. Lemmies tend to overlook this and declare victory over Google when this was merely the first battle of the war.
It will be a "landmark" case, regardless of what the outcome is.
On that we are agreed. The headline speaks of a landmark ruling, which I think is too much acclaim for a decision a higher court could just dismiss.
91% accuracy is the kind of thing that may sound good… hey! It’s an A minus! But it’s actually completely, totally unacceptable. Imagine if the turn signal wand on your car operated with 91% accuracy. About one in every ten times it would light up the wrong direction. How many accidents are we causing? A lot.
Even the number is a bit misleading. First of all, anyone who has ever done LLM benchmarking knows that this isn’t an exact science, at all. You can totally get a 99% on a benchmark and fail every single task on another.
But even this particular claim is nuanced. From the original article:
But with Gemini 3, Google’s A.I.-generated answers were more likely to be ungrounded than when the system was based on Gemini 2, meaning the websites they linked to did not completely support the information they provided. In October, correct answers were ungrounded 37 percent of the time. In February, with Gemini 3, that figure rose to 56 percent.
See https://www.nytimes.com/2026/04/07/technology/google-ai-overviews-accuracy.html
Meaning that 56% of the time, users cannot even verify the information given by the LLM with the sources the LLM claims it’s using.
Whether 91% accuracy is acceptable depends on how unacceptable the 9% inaccuracy is. If 91% of the information in your term paper is correct you'll probably get a decent grade, but if you only kill 91% of cancer cells the surviving 9% will grow a treatment-resistant tumor and you'll probably die. This makes percentages essentially useless - more important is how badly wrong the worst wrong result is.
So whether it’s acceptable depends on whether it’s acceptable. I agree!
This is why we should ban cars outright. Go back to writing on paper. I can stick a pen in my ass and make a cute drawing of a cat. In fact, I might be able to eat a cat and defecate it later, to make it more realistic. And that's what we need to be; realistic.
(This comment is about AI data centers)
I make this "comment" every once and a while because I called someone out on how their post made little sense by parodying it, and now I just do this.
I’m glad you’re entertaining yourself because I have no idea what you’re prattling about.
I'm drawing attention to my educational (f)art project while simultaneously goading someone who thought a less-hyperbolous but still nonsensical analogy was the greatest tweet anyone's ever made. I mean, I remember the first time something I did got seen by millions, so I can understand their enthusiasm to defend it, at the same time, we're still talking about AI data centers, right? I am, at least.
[mimes bong hit]
Bro, that's assault. I am the bong.
While this is a solid ruling and establishes great precedent, it's in Germany and so likely will only eventually apply to the EU. It would be cool to see a similar decision from a US court.
If Google wants to stick with its AI push, I can't imagine they would want to keep training 2 different models; especially if one of them could land them in more hot water down the road. While it would eventually apply to the EU, I can imagine the rollout would be global. Similar to how Apple was forced by the EU to ditch their proprietary connector for USB-C: instead of having an EU & North American model; they just adapted USB-C across all their devices
I imagine the play will be to not offer AI anything in Germany and fan the flames of "we're being left behind in technology"* paranoia amongst politicians until they legislate a special carve out.
* Not my opinion, but it is a thing that the briefcase class likes to say to each other to give them an excuse to dome off big tech CEOs.
Hahahahahahahahahahahhahahahahaa! YES!
Based.
Oh woe, we just wanted to give y'all some cool and useful feature!
Just think of it, why would a greedy corporation want to give you a computation-heavy feature for free, for all your everyday searching purposes? One that would be easy to withdraw instead of fighting in courts over it.
Especially if that corporation has full control over specific results served to you on your query
They'll make them click on a liability agreement every time they try to use it.
That doesn't fly everywhere in Europe
Yes! They are responsible. They're not quoting, they are hallucinating crap they think someone else wrote somewhere.
I mean yeah? This is the only way to square the circle. Same as if you buy a thing from amazon, it does not matter what they try to pull in the back you went and bought a thing from a place. If you google a thing and google shows a wrong (and often plain dangerous) answer then yeah, that counts as google! Maybe if they did not also try and fake the result being true they could have an argument.
And there is already precedence for this as a few nation's courts have found that a company is bound by promises made by their own AI agents that it empowers to answer customers. This is just the same idea but for search. I hope it goes though all the German courts and is picked up in other places.
Can anyone explain how the appeals system works in German courts? I have no idea how the law works in Europe, but it can't be that different from America that there's a chance this could get overturned in appeals, right?
I don't know how the German appeals system works, but there is a lot of room for difference.
A particular reading spree once caused me to learn that the UK, a modern civilized country, didn't have what we would call a supreme court until 2009.
Their laws aren't codified. We have a big book o' laws, and we pass bills that modify the book. If it's not in the book it's not a law. They pass bills that are the laws. This sounds really similar until you consider that "the law" is a collection of every act of parliament going back nearly a thousand years, many of which cancel out others. Oh, and that extends to the concept of a "constitution".
Some quick searching shows that Germany uses a fundamentally different legal model that views our big book o' laws as unstructured because courts have a binding say in interpretation of the law. It seems that this regional court can be appealed, and also that their courts don't use precedent like ours do, so an appeal is more like a second opinion than an escalation.
Judges are less referee and more investigator, so you can claim that the judge made a mistake with their decision, which is appeal.
Oh and the US and UK share what is called "common law" system as well in which decision by the courts are able to referenced as what the law is as well.
So if the legislator writes a law making apples illegal, but a court decided that wasnt true for guys named John, then when someone is charged for it they could cite the "not Johns" ruling as why it shouldn't apply to them.
Yup, that's the precedent bit I mentioned. They're both valid ways of deciding ambiguity (a judge decides in this situation and other judges aren't obligated to decide the same way, or lawyers debate the ambiguity, a jury decides, and courts strive for consistency), but they're fundamentally different and slightly bewildering to people from the other model.
Purely an answer to the question "I mean, how different could they really be?”: fundamentally different in an almost unrecognizable way.
Interesting showstopper for the AI-Bubble. Let's see where this is going.
I don’t use Google, but DuckDuckGo Search Assist often shows summaries with links that don’t at all support what the summary says, but I often still forget to fact check it. I might start using the no AI version of the site because I’m concerned I might accidentally register something important as factual at some point that isn’t.
Awesome news
Okay, but how do you prove any specific allegation when the responses are dynamic?
Take a screenshot
Do you take screenshots of all of your prompts just in case you need to litigate later?
All they need to do is use the exact text from the answers and attribute them to the source...
So, search?
Traditional search does not take you to the relevant portion of the site.
Neither does an AI generated text.
Yes, that is the problem I alluded to...
Quoting sources verbatim is text search. That’s the whole point.
You don’t need generative AI when there’s nothing to generate.
The AI is not just generative, once again, it is used to interpret the question and surface a specific answer to the question instead of just linking to the entire page.
Again, if the result is a quote verbatim, it’s just text search.
There is no difference between traditional search results, where a highlighted quote of the searched topic is presented, and what you propose.
You can keep repeating the same nonsense over and over and it doesn't make it any more correct. I've repeatedly explained how it's not the same.
First of all, you don’t have any notion of how LLMs work, so you cannot “explain” anything.
But even if you did, the idea that a LLM should just interpret a query written in natural language, and return the results for that query quoted verbatim from the source, is so close to how traditional search has been implemented for the past decade or so, it’s hilarious that anyone would propose an alternative to it that is ten times more expensive and not nearly half as precise.
Regardless of all this, “what if we had LLMs that quote text verbatim” is not an explanation, it’s wishful thinking. It’s like saying that if we had flying cars, traffic jams would go away, then proceed to ignore the fact that cars don’t fly, and even if they did, they would be way more expensive, and even if they weren’t, they would create other issues like the need for air traffic control. Silly ideas are a dime a dozen.
the results for that query quoted verbatim from the source, is so close to how traditional search has been implemented for the past decade or so
That's never how it's worked. Traditional search engines just point to links.
I’ll bite. How do you think a LLM could accomplish what you want to do without using RAG, which necessarily involves a search engine?
In other words, what you want is a natural language parser than then goes to a search engine and retrieves content from a website to construct an answer that must quote verbatim the site. Which is what they have been doing for years.
Also, search engines do quote websites, all the time. Are you stuck with Altavista or something?