

dam
17d 7h ago in lemmyshitpost from gregtech.eu
Ghana’s parliament passes a bill criminalizing the promotion of LGBTQ activities
18d 7h ago in world from apnews.comMy original comment was poorly worded. Ghana gained independence 69 years ago, not 200.
The kidnapping and exploitation was in full swing 200 years ago, but it started earlier than that and ended way later, if ever.
Plunder a country
Kidnap their people to make slaves
Impose anti-gay laws on them
200 years later: They are expanding the anti-gay laws! Why are they so backward?!
Pay reparations or shut up.
Why is AI dialogue so fucking bad?
1mon 21h ago in nostupidquestionsTop tier post. Can't wait for the experts at awful.systems to come explain. The question by OP is a very good question so I am sure we will get expert explanations from users of the awful.systems instance.

Orthrus-Qwen3: up to 7.8×tokens/forward on Qwen3, identical output distribution
1mon 2d ago in localllama@sh.itjust.works from github.comThey said they're working on Orthus for Qwen 3.5. It'll be amazing!
My oversimplified and possibly wrong understanding: this is like speculative decoding, but instead of a separate draft model (which does its own prompt processing), they use some diffusion thing strapped on top of the main model. The diffusion reuses the high-quality prompt processing result of the main model.
The 7.8x faster claim sounds almost too good to be true. But even if we get like 3x then this is still a huge revolution in localLLMing.

gas powered rule
1mon 15d ago in onehundredninetysix@lemmy.blahaj.zone from lemmy.blahaj.zone1.5 hours runtime for like half a liter of gasoline?? That's unbelievably inefficient. A half-liter of gasoline is like 15MJ, should power a laptop drawing 30W for a week.
Maybe it would be better with a fuel cell.
How France’s Mistral Built A $14 Billion AI Empire By Not Being American
1mon 21d ago in europe@feddit.org from www.forbes.comIf you would rather not trust any AI company with your data, consider heading to localllama@sh.itjust.works where self-hosted LLM are discussed!
I see. Mistral was the favorite in self-hosted LLM circles back in 2023-2024 but general opinion is that they have since been far surpassed by Chinese and American models, hence my question.
Good to know they've found a market with their online offering.
Is there a use case where Mistral still beat Qwen or Gemma? If you're using Mistral, which model and what do you use it for?

2nd rule
1mon 25d ago in onehundredninetysix@lemmy.blahaj.zone from mander.xyz
"content curation"
4mon 15d ago in memes@lemmy.ml from lemmy.ml
Private donors pledge 860M EUR for CERN's Future Circular Collider
4mon 16d ago in science@mander.xyz from home.cernPrivate donors pledge 860M EUR for CERN's Future Circular Collider
4mon 16d ago in physics@mander.xyz from home.cernPerformance issues?
8mon 5d ago in mander@mander.xyz
So You Think You've Awoken ChatGPT...
10mon 4h ago in technology@lemmy.zip from www.lesswrong.com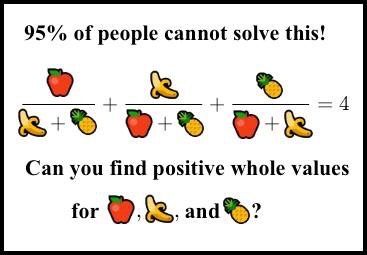
Are you in the 95%?
1y 3d ago in mathmemes@lemmy.blahaj.zone from mander.xyz
someone teach them LaTeX
1y 2mon ago in memes@lemmy.ml from lemmy.ml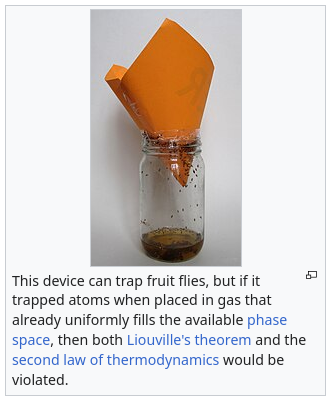
fruit flies are not ergodic
1y 2mon ago in science_memes@mander.xyz from mander.xyz