
Techno-utopist. Sounds like a tech-bro who wants to see capitalism end.
Robotics. Open Source. Machine learning. Self-improving algorithms. Self-building robots. Hackerspaces.

« Stop Killing Games » : la Commission européenne répond (négativement) à cette initiative portée par plus d’un million de joueurs
1d 2h ago in jeuxvideo@jlai.lu from www.frandroid.comEn fait, la principale barrière à faire de l'Union européenne quelque chose de cool, c'est la Commission européenne. Si on laissait le Parlement s'emparer de ce genre de projet de loi, ils auraient beaucoup plus de chances de passer. La commission est là juste pour tuer les initiatives démocratiques.
Et si je puis me permettre, c'est une demande des pays eux même, qui ne voulaient pas être à la merci d'un Parlement beaucoup plus dur à contrôler.

Trump est arrive a Paris
2d 4h ago in france@jlai.lu from jlai.luÇa devient n'importe quoi les poignées de main secrètes des illuminatis.

Oops
4d 14h ago in localllama@sh.itjust.works from files.ikt.id.auUS: Let's not give an edge to China!
China develops its own tools
US: >_<

Surveillance en magasin : avec l’IA, tous les clients deviennent-ils suspects ?
5d 15h ago in france@jlai.lu from www.60millions-mag.comIl y a une accusation implicite dans ma provocation, mais ce n'est pas une accusation de racisme, c'est l'accusation de passer à des systèmes humains des défauts énormes et de ne pas tolérer un millième de ces défauts dans les systèmes automatiques.
Et je suis désolé, mais la surveillance généralisée, ça fait depuis les années 90 qu'on tire des sonnettes d'alarme et qu'on passe pour des zozos. Ce combat, il est perdu.
Les caméras, elles sont partout. Vos plaques d'immatriculation sont partout. Vos téléphones donnent votre localisation partout, tout le temps. Les flux vidéo sont enregistrés, sont consultés, sont effacés sans aucun respect des règles. Il y a des règles théoriques, mais personne ne se charge de les faire appliquer.
Votre identité est liée à votre carte bancaire, à votre consommation électrique, à vos transports, à vos cartes de transport. Depuis le 11 septembre, on passe pour des complices de terroristes quand on dit que peut-être il faudrait un peu limiter les pouvoirs de la police à traquer tout, tout le temps, partout.
Y a des caméras dans les supermarchés depuis les années 80 mais là, tout d'un coup, comme c'est des systèmes à base d'IA, on se réveille. Oui, désolé de penser que c'est de la défiance non justifiée (au contraire du luddisme, qui était un mouvement social) plutôt que de la vraie révolte contre du fichage généralisé. D'autant plus que les modèles d'IA ont la possibilité d'anonymiser réellement, (attention, je ne dis pas que c'est ce qu'ils font systématiquement, mais un système qui a eu l'aval de la CNIL le fait probablement)
En vrai, foutre des IA plutôt que des magnétoscopes et des personnes derrière des caméras, c'est un progrès de l'anonymisation.
C'est tout à fait possible avec un système d'IA de faire des choses du genre compter le nombre de personnes qui sont entrées et sorties d'un bâtiment sans avoir à stocker les images. C'est tout à fait possible d'avoir un système IA qui enregistre l'information « il reste deux personnes dans le hangar » sans enregistrer le fait qu'ils sont en train de se bécoter.
ici, on parle d’outils qui collectent et nourrissent des algorithmes sans le consentement des usagers à des fins surveillance généralisée
Probablement pas non, les systèmes sont déjà entrainés depuis longtemps et grâce à la CNIL (je le dis sans ironie) c'est risqué de faire une telle chose sans consentement. Aux US ils se gênent pas par contre.
On a pas mal de publis dans tous les sens qui montrent comment certains datasets, même sans intention néfaste à l'origine peuvent introduire des biais, mais il ne faut pas pour autant croire que c'est automatique.
On sait qu'au niveau de la sécurité des vigiles, il y a du racisme systémique, qui est entretenu pour plein de raisons.
Ces raisons n'existent pas dans l'apprentissage de datasets. Il faudrait être maladroit ET mal intentionné pour faire quelque chose d'aussi mauvais que les vigiles humains.
Vaut-il mieux un système automatisé qui génère des fausses alertes sur tout le monde ou un système purement humain qui n'en génère que sur les jeunes racisés ?
Vous avez deux heures.
Une IA vient de faire une découverte mathématique majeure (et personne n'en parle)
10d 7h ago in france@jlai.lu from www.youtube.comBon ok, c'est un peu de la provocation. Ça reste un gros morceau, mais c'est qu'un seul item sur la longue liste des choses à améliorer.
Et surtout, je ne pense pas qu'on va le supprimer d'un coup, je pense qu'on va l'user à la longue. Et que oui, comme tu dis, ça va s'accrocher à son caillou, mais ça va devenir de moins en moins important dans le fonctionnement de l'économie.
Ça paraît aussi inatteignable aujourd'hui que la reconnaissance du mariage homosexuel dans les années 80 mais personnellement, je vois les mentalités progresser et je ne vois pas grand-chose qui puisse endiguer les efforts. Je vois plein de trucs qui peuvent aider à aller plus vite. Mais au moins, je trouve que les choses vont dans le bon sens.
Haha, alors note que par rapport à d'autres personnes dans l'extrême gauche, moi j'ai plutôt tendance à considérer que le capitalisme, c'est à la fois plus facile d'en sortir qu'on le pense, mais également moins fondamental:
C'est une étape importante et nécessaire, mais ça ne nous empêche pas de lutter contre plein d'autres mécanismes d'oppression qui existent et qui ne vont pas magiquement disparaître lorsque l'on va changer la structure de propriété des moyens de production. On aura encore à parler du post-colonialisme, du sexisme, de diverses dérives religieuses... Toutes ces choses-là ne vont pas disparaître par magie, et on peut même les combattre dès aujourd'hui.
Franchement, la publication originale, je ne sais même pas si elle vaut encore le coup d'être citée. Elle démontre un effet sur un dataset particulier (wikitext2) de qualité sur un modèle de 125 millions de paramètres. Ils ont démontré un fait assez évident qui est que lorsque tu as un modèle imparfait qui essaye de prédire un dataset, il fait plein d'erreurs. Et que si tu réinjectes ce dataset plein d'erreurs dans l'entraînement d'un nouveau modèle, il va en faire encore plus. Ce n'est absolument pas garanti que ça se généralise à des plus gros modèles ou à d'autres datasets plus gros qui généralement sont de moins bonne qualité.
Ce n'était pas un résultat particulièrement surprenant, et ce n'était pas un particulièrement bon argument pour dire que les données synthétiques ne fonctionnent pas. C'est un point dans le débat, mais la presse s'en est emparée en faisant croire que le débat était tranché, ce qui n'était absolument pas le cas. Les données synthétiques ont une importance de plus en plus grande et on les utilise tout le temps.
Je compare ça à la publication scientifique qui avait prouvé que la force musculaire d'un bras humain n'était pas suffisante à actionner des ailes (correct) et en a conclu que les humains ne pourraient jamais voler.
PS: wow, pas de balise spoiler! On arrive à la fin de la conversation?
le capital et la compétition
Alors juste pour faire mon relou qui aime bien utiliser des termes précis, en fait le capitalisme et la compétition ça va pas nécessairement de pair. C'est le modèle libéral qui marie les deux. Une économie de marché liée à un capitalisme, c'est ce qu'on appelle le "modèle capitaliste" actuel, mais tu peux tout à fait avoir un capitalisme corporatiste qui assoit des monopoles avec éventuellement de la violence. Ce n'est pas le système libéral dont on a l'habitude, mais c'est quand même un système capitaliste qui permet une accumulation de capital et la création de rentes.
C'est une idée qui peut choquer un petit peu, mais la compétition et l'économie de marché, c'est plutôt quelque chose qui tempère le capitalisme et qui, comme tu fais remarquer, l'incite à s'autodétruire dans une certaine mesure.
Bon, alors, j'explique sans excuser. Je considère que l'expérience libérale qui imaginait que le capitalisme serve un modèle plus démocratique grâce à l'économie de marché a largement échoué. Mais je garde quand même personnellement en tête que la compétition, c'est quelque chose qui vient tempérer le capitalisme plutôt que l'aggraver.
Et l’efficacité de ces procédés me rend très sceptique quand à la possibilité de pendre effectivement les capitalistes avec les cordes qu’iels nous offrent dans leur guerre de compétition.
Alors personnellement, c'est juste un espoir et une vision que j'ai, mais je pense que si le gâteau diminue, les capitalistes vont passer plus de temps à se disputer les parts qui restent qu'à essayer de l'agrandir. Je ne pense pas qu'il y ait besoin de pendre ou de détruire les entreprises capitalistes, juste de démontrer leur inefficacité exemple après exemple.
Si tu compares une entreprise qui a des actionnaires et doit avoir une marge suffisante pour leur fournir des dividendes, et que tu compares ça à une coopérative qui, elle, n'a pas cette nécessité, elle peut être beaucoup plus efficace comme ça. Je pense beaucoup plus que la fin du capitalisme arrivera par des coopératives qui sont plus efficaces que les entreprises à leur propre jeu économique que d'un grand soir ou d'une révolution.
Rappelons d'ailleurs qu'à une époque, on considérait que c'était logique pour un gouvernement de gauche de forcer une certaine quantité de la commande publique de passer par des SCOP, les coopératives ouvrières.
acheter un projet open source
mais aussi en rachetant des projets et en les faisant passer propriétaires.
C'est souvent très difficile au point d'être en pratique impossible dans la plupart des cas d'acheter un projet open source avec beaucoup de contributeurs. Ça arrive qu'un projet open source se ferme, mais ça nécessite d'y avoir réfléchi dès le début et d'avoir pris des précautions pour faire du dual licensing et vraiment s'assurer que toutes les contributions ajoutées soient d'accord avec ce pivot potentiel.
Il y a certaines licences que personnellement je trouve trop dangereuses à considérer ouvertes, comme la BSD ou la MIT, qui autorisent assez explicitement les entreprises à les prendre et à les intégrer à un projet fermé, voire à le revendre sous un autre nom. Mais des licences comme la GPL ou l'AGPL évitent ces écueils.
Mais même avec ces licences plus permissives, le public garde le droit de continuer à créer des forks, en général ce qu'ils appellent une version communautaire, et gardent le droit de continuer le développement du projet de leur côté. Le monde du libre et ses licences sont mieux ficelées qu'on ne l'imagine souvent.
Sur le reste, oui, c'est clair qu'il y a une opposition. Je ne veux pas donner l'impression que je pense que les boîtes privées et le monde du libre sont de grands amis. Mais on a deux avantages principaux. Le premier, c'est qu'il n'y a pas une seule force du capital. Il y a plein d'entreprises en compétition et parfois, la victoire de l'une fait avancer l'open source.
La deuxième, c'est que les licences agissent un peu comme un cliquet anti-retour. Les victoires du libre sont assez difficiles à contester plus tard. C'est toute la subtilité d'avoir adossé les licences publiques aux lois qui entourent le copyright.
On utilise les mêmes outils juridiques pour faire défendre les obligations liées aux licences du libre que les capitalistes n'utilisent pour lutter contre le piratage. Ce n'est pas par adhésion idéologique à ces outils, cc'est au contraire, une forme de subversion que je trouve particulièrement délicieuse.
Chirurgie sur modèles: activation steering
Mes sources sur ces manipulations de modèles ne sont pas très récentes, elles datent de l'époque de Llama 2.
Une recherche rapide me montre ce site qui peut t'amuser, je n'ai pas regardé en détail encore.
Mais là, tu vas voir l'exemple d'une petite modification qui montre qu'un modèle peut, sans entraînement supplémentaire, être amené à, dans cet exemple, donner des conseils pour de la fraude fiscale.
Tu peux cliquer sur leur icône Paper pour avoir la publie scientifique qui explique comment ils ont fait.
Ça ne marche que sur les modèles ouverts dont on peut voir les activations intermédiaires et que l'on peut triturer directement. Le but du jeu est de trouver quels vecteurs ajouter dans leurs "processus de réflexion" internes pour les pousser vers plus ou moins d'obséquiosité dans les expériences classiques. Mais également dans ce que j'ai pu voir sur les expériences sur les modèles chinois, vers moins de censure gouvernementale.
Sur le triptyque dataset/fine-tuning/infrastructures
Je suis d'accord avec tes conclusions :-)
Même pour les très gros modèles, je pense que les grosses boîtes n'ont pas davantage d'infrastructures. Avec juste une exception pour l'entraînement de ces gros modèles, où là c'est un savoir-faire encore un petit peu spécialisé j'ai l'impression, et où là aussi il y a l'air d'y avoir des sauces secrètes.
Il y a quand même un enjeu de souveraineté à avoir les infrastructures nécessaires pour entraîner les très gros modèles, les "modèles frontières".
Alors personnellement, je suis de l'opinion qu'ils arrêteront de grossir et que GPT-4 était vraisemblablement le plus gros modèle qu'on n'entraînera jamais. Mais c'est une opinion personnelle, ce n'est pas une certitude à 100%. Du coup, ce n'est pas idiot non plus de stratégiquement garder un savoir-faire de dataset en entraînement pour le cas où, dans deux ou trois ans, on se rende compte que des modèles dix fois plus gros sont nécessaires pour certaines tâches.
Sur les datasets, oui, je pense qu'à moins d'une réforme du copyright, on reste toujours bloqué comme ça.
J'essaie juste de donner un petit peu de perspective sur les accusations de pillage de droits d'auteur auxquels on a le droit dès que les gens commencent à comprendre comment sont assemblés ces datasets. Jetez pas la pierre à ceux qui avouent qu'ils le font, parce qu'ils le font vraiment tous. Et ne jetez pas non plus la pierre à ceux qui ne font que du open weight, parce que souvent, légalement, ils n'ont pas la possibilité de faire vraiment du vrai open source.
Assez curieusement, les meilleurs modèles complètement open source dont les datasets et les procédures d'entraînement sont publiés sont probablement ceux de Nvidia. Pas exactement un grand fan de l'open source.
Mais là encore, c'est une boîte privée qui a trouvé son intérêt dans l'open source. Eux, leur but, c'est de vendre du matériel. Et plus il y a de modèles ouverts, performants, plus il y a de gens qui ont envie d'entraîner, de fine-tuner des modèles. Plus ils vont vendre de matos. Et c'est d'autant plus facile à faire qu'on dispose de bons modèles ouverts. Donc eux publient des modèles ouverts avec les datasets, se sont pris dans la gueule tous les procès auxquels on pouvait s'attendre, mais eux ont des avocats pour se défendre.
Et en fait, on a quelque chose qui va probablement nous débloquer dans les prochaines années sur la question des datasets. C'est ce qu'on appelle les datasets synthétiques. Et c'est une décision un petit peu étrange également qui a été prise par une cour américaine de déclarer que les sorties d'un modèle génératif ne tombent pas sous le coup du copyright.
Les données synthétiques, c'est un concept très simple. c'est qu'au lieu d'entraîner un modèle sur un dataset de sources variées, on va l'entraîner principalement sur les sorties d'un autre LLM qu'on sait assez bon. Contrairement à une croyance populaire qui vient d'une publi qui est a été assez mal comprise par le grand public, ça ne rend pas les modèles moins bons de faire ça, en tout cas pas sur une génération.
Et là, bon courage pour m'attaquer si je dis que moi j'ai payé pour un service en ligne qui a priori est légal, n'a jamais été reconnu comme étant dans l'illégalité et pour lequel j'ai payé pour des tokens que la loi considère ne pas être sous copyright. Ça va être assez difficile de m'accuser d'avoir violé du copyright indirectement ou d'interdire mon modèle.
Donc personnellement, je ne considère pas qu'il y ait une énorme incertitude légale là, mais c'est pour dire qu'il ne faut pas forcément jeter la pierre aux groupes qui ne publient pas leur dataset. Il y a une inégalité de moyens qui est vraiment problématique pour les communautés libres.

I Tried This Open Source ChatGPT Alternative [Jan AI] on Linux, But Went Back to Ollama
15d 6h ago in localllama@sh.itjust.works from itsfoss.comJust to know if you are not aware, you are putting a penny in a hot debate in the free software community on which license is the more open, is the best.
The MIT is clearly the most permissive because it allows you, among other things, to just run with the software and close it, adding your modification and sell it without sharing source.
Afero GPL prevents you from selling the software or even selling services that run the software without sharing/publishing it.
In a MIT->AGPL swap you will find people who consider it a step into being closer to free software ideals and people who consider it getting further away from it.

Changement climatique - on s'adapte...
22d 12h ago in forumlibre@jlai.lu from tarte.media.nuage-libre.fr
Mistral a un problème d'alignement éthique - DystopiaBench
28d 14h ago in technologie@jlai.lu from dystopiabench.com
RIP HADOPI (2009–2026)
1mon 16d ago in france@jlai.lu from www.laquadrature.netDémo du robot de Mistral, et surtout de leur modèle, Robostral WMa1
3mon 12d ago in france@jlai.lu from old.reddit.com
Les Ecologistes remettent le référendum d’initiative citoyenne au menu du débat parlementaire
4mon 5d ago in france@jlai.lu from www.lemonde.fr
« Transmettre les entreprises de père en fils est absurde » : Edouard Sauer, ce patron qui voudrait léguer son entreprise à une fondation humanitaire
4mon 11d ago in france@jlai.lu from www.lemonde.fr
Debout! - Les Bâtisseurs - Régions et Peuples solidaires - Péyi-A - Combien de petits partis présent à l'AN connaissez vous?
5mon 4d ago in france@jlai.lu from europeelects.eu
Municipales 2026 : après LR, Horizons soutient à son tour Louis Sarkozy, candidat à Menton
5mon 29d ago in france@jlai.lu from www.leparisien.fr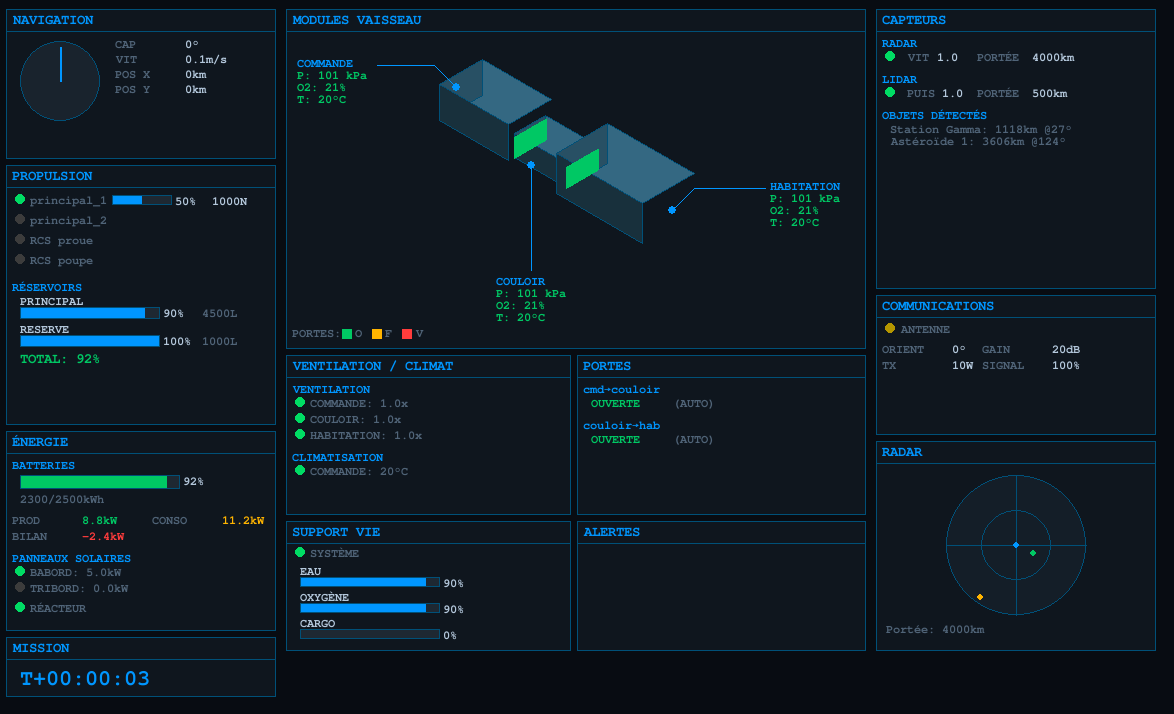
Le dimanche c'est vibe coding
6mon 19d ago in technologie@jlai.lu from tarte.media.nuage-libre.fr